ビッグデータとは一体何なのか、そしてなぜそれが正確な視聴者測定への贈り物であると同時に障害となり得るのか。その長所と短所、そしてビッグデータをうまく活用する方法を探る。
ビッグデータとは何か?
リニアメディアの世界では、ビッグデータは通常、番組をエンドユーザーに配信するシステムによって生成される2種類のデータストリームを指す:ケーブルや衛星放送のセットトップボックス(DishやDirecTVなど)からのリターンパス・データ(RPD)と、インターネットに接続されたスマートテレビ(SamsungやVizioなど)からの自動コンテンツ認識(ACR)である。


ACRデータ
チャンネル変更のログではなく、ACR技術はテレビ画面上の画像をモニターする。画像はフィンガープリントのような役割を果たし、大規模な参照ライブラリーと比較され、番組や広告が実際に何であるかを特定する。画像にはタイムスタンプが押され、いつ再生されたかを把握することができる。
RPDデータ
セットトップボックスがどのチャンネルに合わせられ、何時にチャンネルが変更されたかを記録する。そのデータをテレビ番組表と照合することで、その時間にどの番組が放送されているかを特定したり、プロバイダーの広告サーバーやパートナーからのデータと照合することで、その家庭がどのような広告に接触しているかを把握することができる。
どちらの場合も、エンドユーザーは自分のデバイスでのデータ収集を許可している。データ収集は測定だけでなく、ユーザー嗜好やコンテンツ推薦のような望まれる機能も駆動するため、協力は比較的高い。RPDやACRのデータセットは、3,000万台以上のデバイスをカバーしているかもしれない。
ビッグデータはなぜ重要なのか?

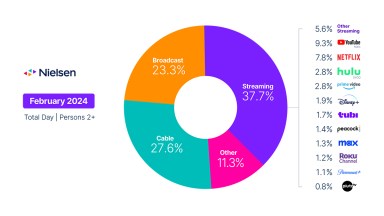
かつて、人々が選べるチャンネルが限られていた時代があった。世帯視聴率1が60(1983年の『M★A★S★H』のフィナーレのようなもの)以上、あるいは40(1998年の『となりのサインフェルド』のフィナーレのようなもの)以上というのは、今日の脚本番組では考えられないことだ。私たちは、より細分化された世界に生きており、番組の選択肢は非常に長い長いリストにある。
テレビ視聴者にとっては素晴らしいことだが、パネルベースの調査にとっては複雑なことだ:全国1億1000万人のパネルでは、視聴率0.2のテレビ番組は80世帯で視聴され、アトランタやダラスの都市部では1世帯しか視聴されないかもしれない。何千万台ものデバイスを測定対象とするビッグデータによって、調査会社はテレビの利用状況をより詳細なレベルで報告することが可能になり、視聴者が少人数でしばしば多様な、より多くの番組をカバーすることができるようになった。しかし、ビッグデータはそれ自体、視聴者測定に使われることを意図したものではない。
課題その1:ビッグデータは代表的なものではない
自信を持って取引するためには、メディアの買い手と売り手は、人口の多様性をすべて反映した測定ソリューションを必要としています:すべての年齢層、人種、民族、その他多くの主要な人口統計学的および行動学的特性が、基礎データに存在し、比例している必要があります。
しかし、規模が代表性を保証するわけではない。ニールセン・ナショナルTVパネルの設置台数を分析したところ、RPDのある家庭は、一般人口に比べ、年齢層が高く、人種的多様性に乏しいことがわかった。例えば、ヒスパニック系の世帯は、ニールセンについて 30%少なく、25歳未満の世帯主はRPDデータセットにほとんど含まれていません。一方、ACRデータセットは一般人口より若く、世帯員数も多い。ビッグデータで統計的な重み付けを使えば、問題は隠せるかもしれないが、不特定多数の視聴者の欠落した独自の視聴行動を補うことはできない。
さらに悪いことに、RPDとACRのデータだけに頼った測定ソリューションでは、パイの一部を占めつつある放送局2やストリーミングのみの世帯を見逃すことになる。
課題その2:ビッグデータがすべての視聴行動を捕捉しているとは限らない
仮に代表的な世帯が含まれていたとしても、RPDやACRのデータセットは、世帯内のすべてのセットトップボックスセットや、スマートテレビではない家庭内の他のテレビからの視聴を捕捉しているわけではない。そのため、ビッグデータの世帯が母集団を代表していないだけでなく、ビッグデータ自体もその家庭で起きているすべての視聴を代表しているわけではない。

RPDに依存している調査会社にとって不満な問題は、接続されているテレビの電源を切ってもセットトップボックスの電源が入ったままになることが多いことだ。この "ファントム "チューニングは、プロバイダーにもよるが、実際の視聴を145%から260%誇張する可能性がある。それを補正するために実装できるモデルはあるが、実際の視聴から情報を得たパネルのような参照点がなければ、適切なヒューリスティックスを開発するのは難しい。
ACRもデータ品質の問題と無縁ではない。一部のスマートTVストリーミング・アプリケーションは、アプリの使用中にACRが画面上のコンテンツをキャプチャするのをブロックする。コンテンツがアプリによってブロックされているにもかかわらず、テレビがオフになっているように見えることがある。また、ほとんどのプロバイダーは、視聴可能な番組のごく一部しかモニターしていない。最近の分析では、ACRプロバイダーは現在、利用可能な全放送局のわずか31%しかモニターしておらず、録画された分の23%はまだモニターされていない放送局から来ていることがわかった。基準となるフィンガープリントがないため、視聴は報告されない。
課題その3:ビッグデータには視聴者の属性が欠けている
RPDやACRプロバイダーは、何百万台ものデバイスからチューニングデータを取得しているが、広告主が最終的に求めている「誰が見ているか」はわからない。
その欠点を補う一つの方法は、サードパーティの人口統計サプライヤーと組むことである。調査会社は、ある世帯のチューニングデータとその世帯の人口統計学的構成の合計から、誰が何を見ているのかを単純にモデル化しようとするかもしれない。
子供番組?それはきっと、この家の子供がやっているに違いない。プロレスの試合?それは男性視聴者のものに違いない。機械学習アルゴリズムを補助する現実の参照点がなければ、この種のモデリングがどこで破綻するかは容易に想像がつく。当然のことながら、世帯の規模が大きくなるほど信頼性は低下し、結局、子供のいるような大家族、非白人、若年層の視聴者にとっては、データの正確性に支障をきたすことになる。
パネルデータの永続的価値
安定した信頼性の高い視聴者測定ソリューションを求めるブランドやメディア企業にとって、上記のような課題は避けて通れない。これらの限界を克服するためには、パネルデータが不可欠です。
ニールセンでは、RPDやACRのデータを分析する際、どの家庭やデバイスが当社のパネルに含まれているかを特定し、それらの家庭のチューニングデータを当社のメーターが捉えた視聴行動と比較することができます。これらの家庭でパネルを真実のソースとして使用することで、ビッグデータが真実から乖離している箇所を特定し、その異常を調整するための堅牢なモデルを開発することができます。
例えば、あるデバイスが家のどこにあるのかを特定し、そのチューニングデータを特定の視聴者に一致させる手法を開発した。別のモデルは、セットトップボックスがオンになっているときにテレビがオフになっているかどうかを判断するのに役立ちます。さらに別のモデルは、追加チューニングとして登録されたデバイスの更新や、デバイスが同時に複数のチューニングイベントを返す状況を選別することができます。
装置ではなく人

結局のところ、視聴者調査はニールセンについて 、デバイスではなく人である。
ビッグデータがメディア・リサーチャーの武器になることは間違いない。過去には不可能だったような、より詳細な報道への扉を開いてくれる。しかし、それは本質的に欠陥があり、偏りがあり、そして最も根本的には近視眼的である:それは、視聴データではなく、チューニングデータをキャプチャすることである。
そのポテンシャルを発揮するためには、クリーンアップし、記入し、校正し、関連する人口統計で豊かにする必要がある。そこでパネルデータの出番となる。機械学習は、強力な学習データと検証データによって最も効果的に機能します。そして、今日のメディア・リサーチ事業の中核をなす全国代表パネル・データほど優れた学習データは、この業界にはありません。
ニールセンの 視聴者測定の基礎を見直し、メディア業界で最もホットなトピックを解明 します。
注
2 アンテナからの「信号」を通じて視聴できる番組。OTA(Over the Air)放送が最初のテレビである。